Selecting a Randomness Extractor
In general, the choice of randomness extractor depends on the scenario in which it is used, and it is not always clear which extractor is best suited to a given situation. Here, we informally summarize the information from the ‘Overview of Extractor Library’ in [For2024], which assists a user in selecting the best randomness extractor for their task.
If a user begins with some extractor input of length \(n_1\) with min-entropy \(k_1\), the flowchart below provides a useful guide for selecting an appropriate extractor.
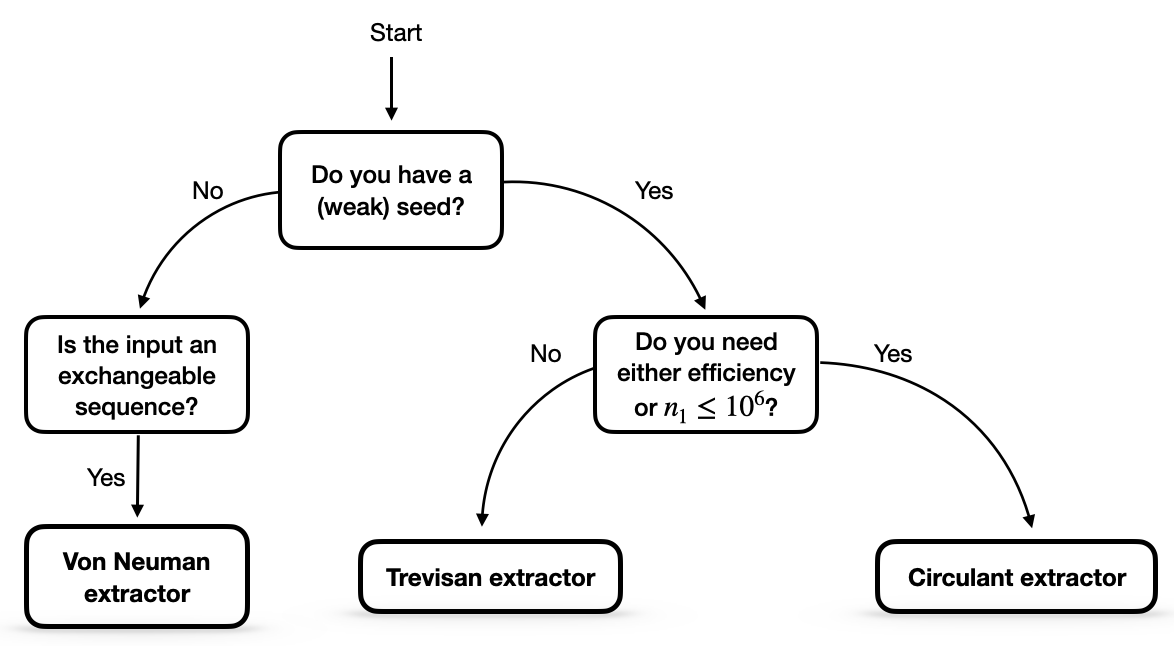
This flowchart gives a good general approach to follow, however, some improvements can be obtained by analyzing each extractor individually. The maximum output length for each extractor in different security models is detailed in the following table, where \(n_2\) and \(k_2\) denote the length and min-entropy of the (weak) seed, respectively and \(\epsilon\) the extractor error.
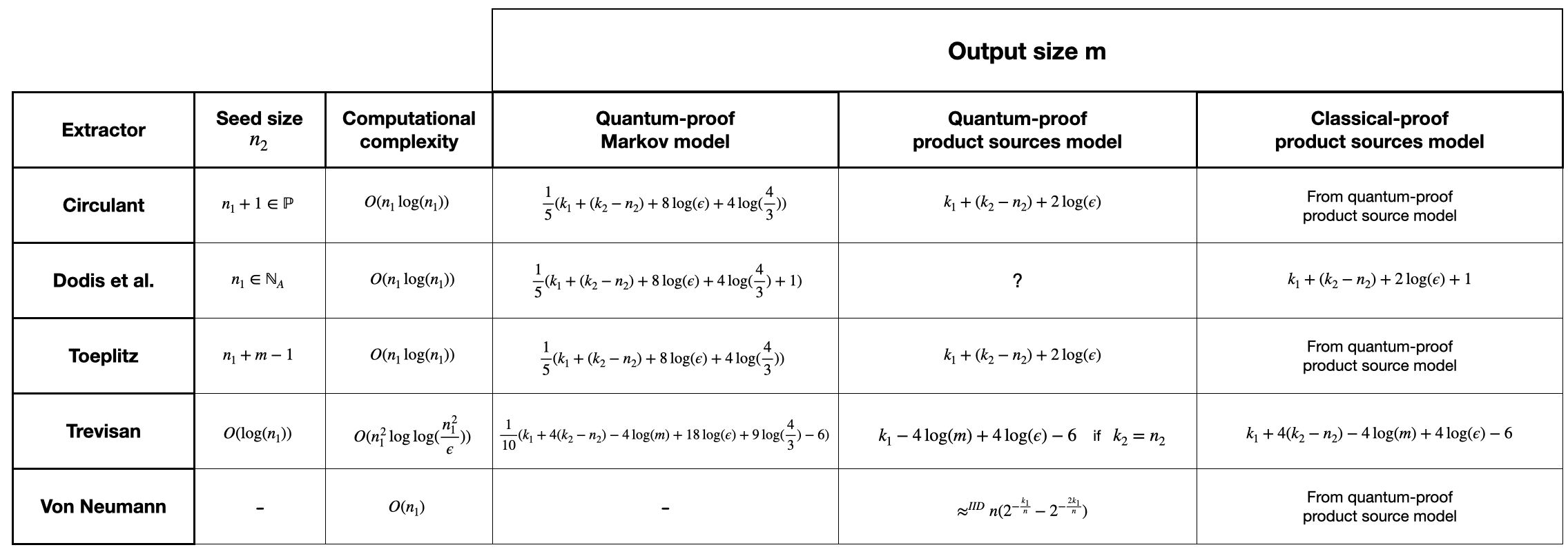
The derivation of these parameters and all relevant proofs can be found in [For2024].