Quantum pipeline using the Quantum Trainer
[1]:
import warnings
warnings.filterwarnings("ignore")
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
[2]:
import numpy as np
BATCH_SIZE = 30
EPOCHS = 120
SEED = 2
Read in the data and create diagrams
[3]:
def read_data(filename):
labels, sentences = [], []
with open(filename) as f:
for line in f:
t = int(line[0])
labels.append([t, 1-t])
sentences.append(line[1:].strip())
return labels, sentences
train_labels, train_data = read_data('datasets/mc_train_data.txt')
dev_labels, dev_data = read_data('datasets/mc_dev_data.txt')
test_labels, test_data = read_data('datasets/mc_test_data.txt')
Create diagrams
[4]:
from lambeq import BobcatParser
parser = BobcatParser(verbose='text')
raw_train_diagrams = parser.sentences2diagrams(train_data)
raw_dev_diagrams = parser.sentences2diagrams(dev_data)
raw_test_diagrams = parser.sentences2diagrams(test_data)
Tagging sentences.
Parsing tagged sentences.
Turning parse trees to diagrams.
Tagging sentences.
Parsing tagged sentences.
Turning parse trees to diagrams.
Tagging sentences.
Parsing tagged sentences.
Turning parse trees to diagrams.
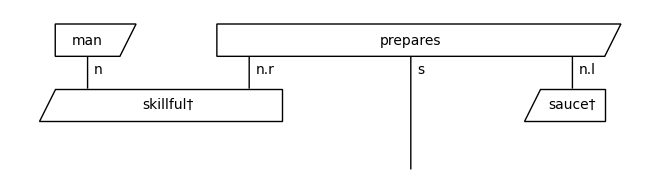
Remove the cups
[5]:
from lambeq import RemoveCupsRewriter
remove_cups = RemoveCupsRewriter()
train_diagrams = [remove_cups(diagram) for diagram in raw_train_diagrams]
dev_diagrams = [remove_cups(diagram) for diagram in raw_dev_diagrams]
test_diagrams = [remove_cups(diagram) for diagram in raw_test_diagrams]
train_diagrams[0].draw()
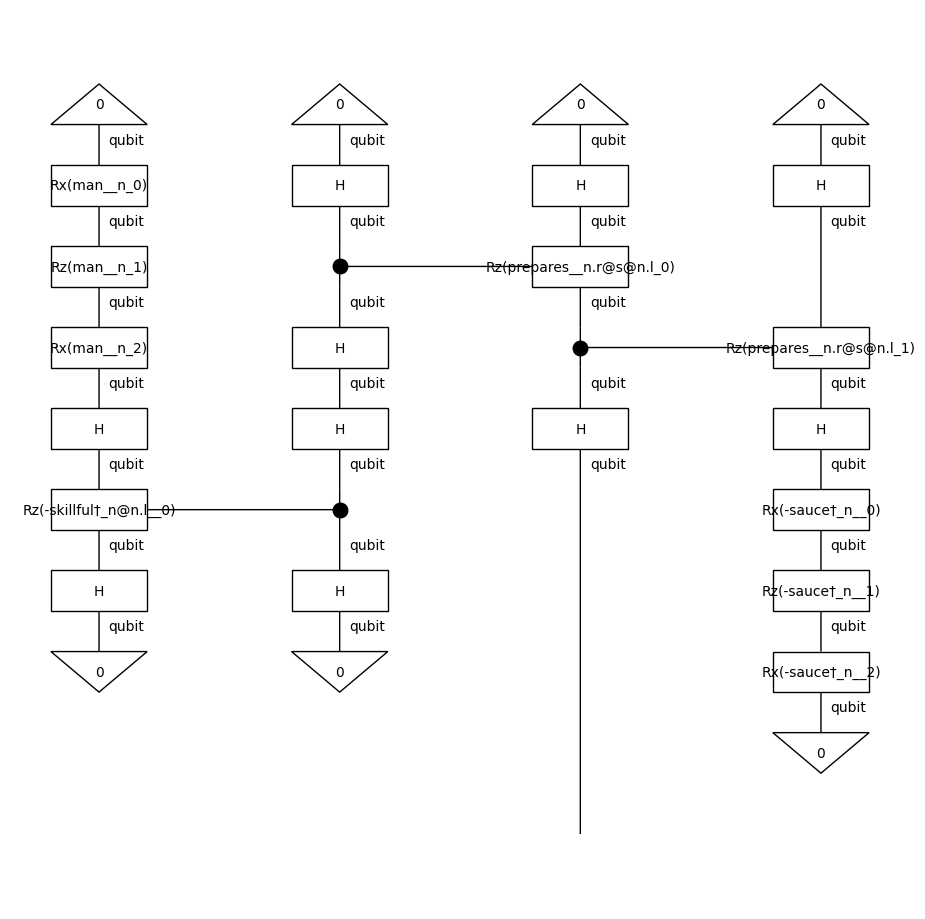
Create circuits
[6]:
from lambeq import AtomicType, IQPAnsatz
ansatz = IQPAnsatz({AtomicType.NOUN: 1, AtomicType.SENTENCE: 1},
n_layers=1, n_single_qubit_params=3)
train_circuits = [ansatz(diagram) for diagram in train_diagrams]
dev_circuits = [ansatz(diagram) for diagram in dev_diagrams]
test_circuits = [ansatz(diagram) for diagram in test_diagrams]
train_circuits[0].draw(figsize=(9, 9))
Parameterise
[7]:
from pytket.extensions.qiskit import AerBackend
from lambeq import TketModel
all_circuits = train_circuits+dev_circuits+test_circuits
backend = AerBackend()
backend_config = {
'backend': backend,
'compilation': backend.default_compilation_pass(2),
'shots': 8192
}
model = TketModel.from_diagrams(all_circuits, backend_config=backend_config)
Define evaluation metric
[8]:
from lambeq import BinaryCrossEntropyLoss
# Using the builtin binary cross-entropy error from lambeq
bce = BinaryCrossEntropyLoss()
acc = lambda y_hat, y: np.sum(np.round(y_hat) == y) / len(y) / 2 # half due to double-counting
Initialize trainer
[9]:
from lambeq import QuantumTrainer, SPSAOptimizer
trainer = QuantumTrainer(
model,
loss_function=bce,
epochs=EPOCHS,
optimizer=SPSAOptimizer,
optim_hyperparams={'a': 0.05, 'c': 0.06, 'A':0.01*EPOCHS},
evaluate_functions={'acc': acc},
evaluate_on_train=True,
verbose = 'text',
seed=0
)
[10]:
from lambeq import Dataset
train_dataset = Dataset(
train_circuits,
train_labels,
batch_size=BATCH_SIZE)
val_dataset = Dataset(dev_circuits, dev_labels, shuffle=False)
Train
[11]:
trainer.fit(train_dataset, val_dataset, log_interval=12)
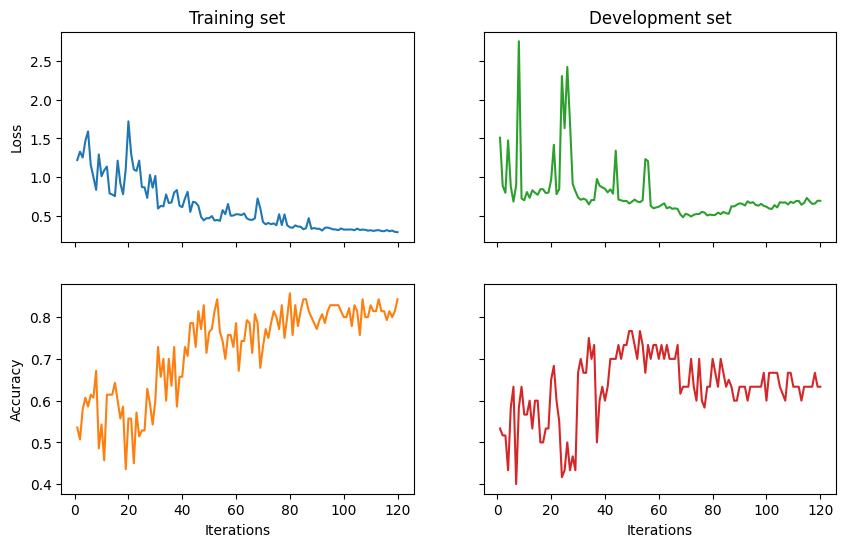
Epoch 12: train/loss: 0.7806 valid/loss: 0.7370 train/acc: 0.6143 valid/acc: 0.6000
Epoch 24: train/loss: 0.8200 valid/loss: 2.3029 train/acc: 0.5143 valid/acc: 0.4167
Epoch 36: train/loss: 0.5799 valid/loss: 0.7074 train/acc: 0.6357 valid/acc: 0.7333
Epoch 48: train/loss: 0.2536 valid/loss: 0.6971 train/acc: 0.8286 valid/acc: 0.7333
Epoch 60: train/loss: 0.3525 valid/loss: 0.6221 train/acc: 0.7857 valid/acc: 0.7000
Epoch 72: train/loss: 0.4108 valid/loss: 0.4954 train/acc: 0.7500 valid/acc: 0.7000
Epoch 84: train/loss: 0.3844 valid/loss: 0.5546 train/acc: 0.8143 valid/acc: 0.6667
Epoch 96: train/loss: 0.4692 valid/loss: 0.6456 train/acc: 0.8286 valid/acc: 0.6333
Epoch 108: train/loss: 0.3136 valid/loss: 0.6517 train/acc: 0.8000 valid/acc: 0.6667
Epoch 120: train/loss: 0.1469 valid/loss: 0.6978 train/acc: 0.8429 valid/acc: 0.6333
Training completed!
Show results
[12]:
import matplotlib.pyplot as plt
fig, ((ax_tl, ax_tr), (ax_bl, ax_br)) = plt.subplots(2, 2, sharex=True, sharey='row', figsize=(10, 6))
ax_tl.set_title('Training set')
ax_tr.set_title('Development set')
ax_bl.set_xlabel('Iterations')
ax_br.set_xlabel('Iterations')
ax_bl.set_ylabel('Accuracy')
ax_tl.set_ylabel('Loss')
colours = iter(plt.rcParams['axes.prop_cycle'].by_key()['color'])
range_ = np.arange(1, trainer.epochs + 1)
ax_tl.plot(range_, trainer.train_epoch_costs, color=next(colours))
ax_bl.plot(range_, trainer.train_eval_results['acc'], color=next(colours))
ax_tr.plot(range_, trainer.val_costs, color=next(colours))
ax_br.plot(range_, trainer.val_eval_results['acc'], color=next(colours))
test_acc = acc(model(test_circuits), test_labels)
print('Test accuracy:', test_acc)
Test accuracy: 0.7666666666666667